Creating Jobs
Jobs are the combination of a registered task, input arguments & any subsequent actions that need to be performed.
Jobs can be created 3 ways:
EasyJobsManager API
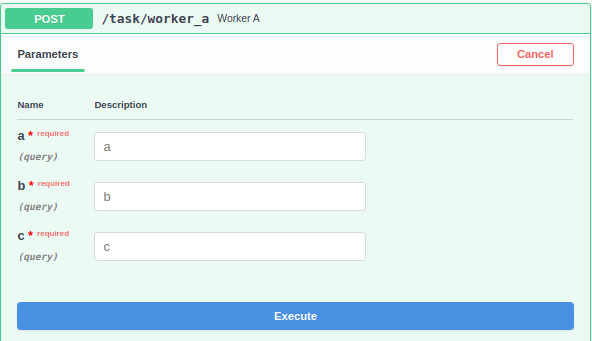
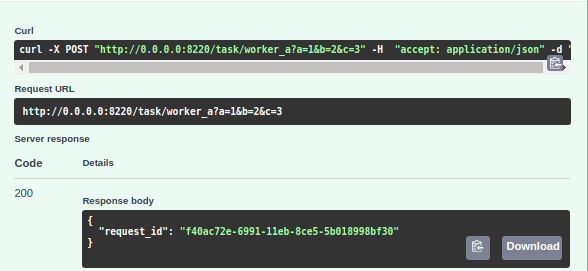
- Invocation of a job via the API will return a request_id indicating the request was added to the persistent queue.
- A job will be created as soon as a worker is able to respond to the job creation request.
- Created Jobs are then added to a secondary queue with the associated job parameters(run_after, retry_policy, etc..)
- Workers with free task reservations will start and run job ASAP.
Note
The jobs visible in the OpenAPI are dynamically added, even after startup. Newly added Workers Namespaces or registered Functions will be visible by simply refreshing the /docs page.
An important feature of EasyJobs is signature cloning of registered functions locally & for remote workers. This allows for immediate argument verification before the request is queued.
Message Queues
Jobs created in message queues should match the following format, using json serializable data. If you can run json.dumps(data) on the data, you can use it in a job.
job = {
'namespace': 'name' # also known as queue
'name': 'name',
'args': [args],
'kwargs': {'kwarg': 'val'}
}
Tip
See Producers - to review how to create jobs.
Tip
Think about how you would invoke he job if local, then create the syntax using a Producer.
When a Job is added ( either pulled from a broker, or pushed via producer) the job is first added to a persistent database, then added to a gloabal queue to be run by workers monitoring the queue.
Schedule
Tasks may be configured with a cron schedule that invokes the task with the default_arguments provided.
Job Life Cycle
- A Job may created if pulled from a Message Queue, OnDemand via the EasyJobsManager API, or by a schedule
- The Job is added to the jobs database and queued for worker consumtion.
- A Job is selected by a worker. Any dependent Jobs listed in run_before are scheduled and must complete.
- After dependent jobs, Job is invoked with the provided args / kwargs parameters( if any ).
- Job Failures result in triggering a retry followed by any task on_failure tasks ( if any ), then reported as failed to EasyJobsManager's results database / queue.
- Job Successes result in creating any task run_after tasks using the results of the last job, then reporting the results to EasyJobsManager's results database / queue.
- Results are stored within the EasyJobsManager Database
Consuming Results
When a job request is created via the API, a request_id is returned right-away.
Note
Results of run_before methods are consumed automatically.
View Job Result
Will return status of Task (Queued / Running / Failed / Completed)
Pull Job Result
will wait up to 5 seconds for a job to complete, returning the consumed result.
Danger
Once a result is consumed via Pull Job Result, the results will no longer be visible.
Pausing Workers
Under certain circumstances it can be advantageous to prevent workers from pulling new jobs to run. - high worker utilization, or too many jobs running - draining a worker for maintenance
Tip
Job processing for EasyJobsManagers or EasyJobsWorkers can be paused using toggle_workers
EasyJobsManager.toggle_workers(pause=True|False)
EasyJobsWorker.toggle_workers(pause=True|False)
Pausing Example
import psutil
from easyjobs.manager import EasyJobsManager
from fastapi import FastAPI
server = FastAPI()
every_minute = '* * * * *'
@server.on_event('startup')
async def startup():
server.job_manager = await EasyJobsManager.create(
server,
server_secret='abcd1234'
)
@server.job_manager.task()
async def basic_task(a: str, b: int, c: float):
return {'results': [a, b, c]}
scheduler = server.job_manager.scheduler
@scheduler(schedule=every_minute)
def monitor_utilization():
log = server.job_manager.log
# check server usage
# gives a single float value
high_mem = False
high_cpu = False
mem = psutil.virtual_memory().percent
cpu = psutil.cpu_percent()
log.warning(f"monitor_utilization - cpu {cpu} - mem {mem}")
if psutil.virtual_memory().percent >= 35.0:
server.job_manager.toggle_workers(pause=True)
high_mem = True
if psutil.cpu_percent() > 20.0:
server.job_manager.toggle_workers(pause=True)
high_cpu
# finished for now
if high_cpu or high_mem:
return
# resource are ok, unpause
else:
server.job_manager.toggle_workers(pause=False)